Comando iconv no Linux (converte arquivos) [Guia Básico]
O comando iconv no Linux pode ser usado para converter diferentes tipos de arquivos para codificações diferentes.
As opções mais comuns são:
- -l: Lista todos os formatos suportados;
- -f: Estabelece o formato de entrada dos dados;
- -t: Estabelece o formato de saída dos dados;
- -o: Arquivo de saída.

Exemplos:
Neste exemplo o iconv irá converter o arquivo1.txt para saída.txt, convertendo os caracteres da codificação ISO-8859-1 usada geralmente no Windows para o formato do UTF-8:
$ iconv -f ISO-8859-1 -t UTF-8 –o saída.txt arquivo1.txt
A opção -l mostra todos os formatos de codificação suportados pelo iconv:
$ iconv -l
437, 500, 500V1, 850, 851, 852, 855, 856, 857, 858, 860, 861, 862, 863, 864,
865, 866, 866NAV, 869, 874, 904, 1026, 1046, 1047, 8859_1, 8859_2, 8859_3 ( ... )
Padrões de Caractere

Como todo sistema operacional, o Linux precisa trabalhar com vários mapas de caracteres, de forma a cobrir várias línguas e formatos de caracteres.
Para fazer isso, convencionou-se o uso de “Mapas de Caracteres”, que mapeiam um caractere de um determinado alfabeto em uma sequência de bits, que vão compor esses caracteres.
Esses mapas de caracteres são uma convenção utilizada em todo o mundo por diversos sistemas computacionais, e por isso, foram rotulados com nomes e números, para que a conversão dos bits dos arquivos seja possível, na linguagem e caracteres corretos. Isto também possibilita a conversão dos caracteres de um mapa para outro, às vezes com certa perda de dados.
Segue uma breve descrição dos mapas de caracteres mais utilizados.
ASCII
ASCII é um acrônimo para American Standard Code for Information Interchange, que em português significa “Código Padrão Americano para o Intercâmbio de Informação”. Este padrão é uma codificação de caracteres de sete bits baseada no alfabeto inglês.
Os códigos ASCII representam texto em computadores, equipamentos de comunicação, entre outros dispositivos que trabalham com texto. O ASCII foi desenvolvido para uso de telégrafos em 1960 que usavam impressoras de 7-bits. Grande parte das codificações de caracteres modernas a herdou como base.
A codificação define 128 caracteres, preenchendo completamente os sete bits disponíveis. Desses, 33 não são imprimíveis, como caracteres de controle atualmente obsoletos, que afetam o processamento do texto. Exceto pelo caractere de espaço, o restante é composto por caracteres imprimíveis.
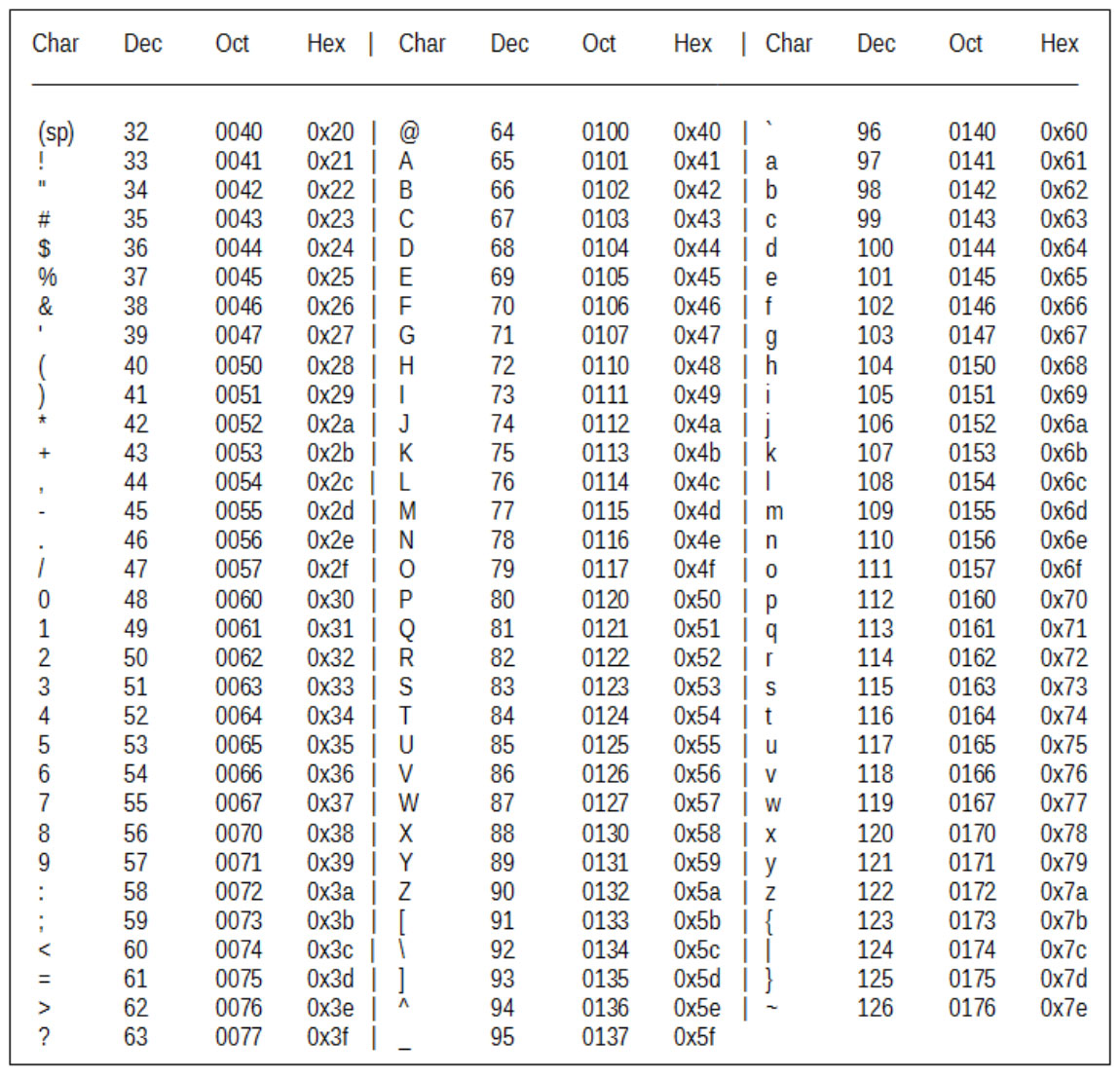 Tabela ASCII Tabela ASCII |
ISO-8859
A maioria dos 95 caracteres imprimíveis do ASCII são suficientes para troca de informações quando se trata de dados escritos em inglês. No entanto, outras línguas latinas e orientais precisam de símbolos para representar os caracteres que não são cobertos pelo ASCII, como as letras acentuadas e outros caracteres.
O padrão ISO-8859 resolveu este problema utilizando uma codificação de 8-bits, possibilitando mais 128 codificações além das 128 existentes no ASCII.
Mesmo com mais 128 símbolos, o ISO-8859 não comportava todos os caracteres especiais que o alemão, espanhol, português, sueco, húngaro, dentre outras línguas necessitavam. Desta forma, eles criaram diferentes mapas de caracteres que fazem parte do ISO-8859, a seguir:
- ISO-8859-1 – Latin-1: Caracteres latinos do oeste europeu. É o mais usado, pois cobre o inglês, alemão, francês, italiano, português, espanhol e outras línguas da região oeste da Europa;
- ISO-8859-2 – Latin-2: Caracteres da Europa central e leste, como polaco, esloveno, sérvio, húngaro etc.;
- ISO-8859-3 – Latin-3: Caracteres do sul da Europa, como turco, e também o esperanto;
- ISO-8859-4 – Latin-4: Caracteres do Norte da Europa, como estoniano, lituano, dentre outras;
- ISO-8859-5 – Latin/Cyrillic: Caracteres usados na Rússia e na Ucrânia;
- ISO-8859-6 – Latin/Arabic: Caracteres árabes;
- ISO-8859-7 – Latin/Greek: Caracteres gregos;
- ISO-8859-8 – Latin/Hebrew: Caracteres hebreus;
- ISO-8859-9 – Latin-5: Caracteres turcos;
- ISO-8859-10 – Latin-6: Usados em línguas bálticas;
- ISO-8859-11 – Latin/Thai: Usados em línguas bálticas;
- ISO-8859-12 – Latin/Devanagari: Usados em devanágari;
- ISO-8859-13 – Latin-7: Adicionou alguns caracteres que ficaram faltando no latin-4 e latin-6;
- ISO-8859-14 – Latin-8: Caracteres celtas;
- ISO-8859-15 – Latin-9: Revisão do latin 1, removendo alguns símbolos pouco usados e adicionando outros;
- ISO-8859-16 – Latin-10: Usados no sudeste europeu para albanês, croata, húngaro, italiano, polonês, romeno e esloveno, mas também finlandês, francês, alemão e irlandês gaélico (nova ortografia). O foco está mais em letras de símbolos. O sinal de moeda é substituído com o símbolo do euro.
UNICODE
Unicode é um padrão que permite aos computadores representar e manipular, de forma consistente, texto de qualquer sistema de escrita existente.
O padrão consiste em um repertório de cerca de cem mil caracteres, um conjunto de diagramas de códigos para referência visual, uma metodologia para codificação e um conjunto de codificações padrões de caracteres, uma enumeração de propriedades de caracteres como caixa alta e caixa baixa, um conjunto de arquivos de computador com dados de referência, além de regras para normalização, decomposição, ordenação alfabética e renderização.
O Unicode é composto de esquemas padronizados de transformação Unicode chamados Unicode Transformation Format, ou UTF.
O seu sucesso em unificar conjuntos de caracteres levou a um uso amplo e predominante na internacionalização e localização de programas de computador. O padrão foi implementado (leia sobre deploy) em várias tecnologias recentes, incluindo XML, Java e sistemas operacionais modernos.
O Unicode possui o objetivo explícito de transcender as limitações de codificações de caractere tradicionais, como as definidas pelo padrão ISO 8859, que possuem grande uso em vários países, mas que permanecem em sua maioria incompatíveis umas com as outras.
O UTF-8 (8-bit Unicode Transformation Format) é um tipo de codificação Unicode de comprimento variável criado por Ken Thompson e Rob Pike.
Pode representar qualquer caractere universal padrão do Unicode, sendo também compatível com o ASCII. Por esta razão, é adotado como tipo de codificação padrão universal para email, páginas web e outros locais.
O “Internet Engineering Task Force” (IETF) requer que todos os protocolos utilizados na Internet suportem, pelo menos, o UTF-8.
Aprenda muito mais sobre Linux em nosso curso online. Você pode efetuar a matrícula aqui. Se você já tem uma conta, ou quer criar uma, basta entrar ou criar seu usuário aqui.
Gostou? Compartilhe
Tag:/dev, bash, certificação, certificaçãolinux, code, Comptia, developer, empreendedorismo, exame, freesoftware, gnu, hack, Linux, linuxfan, linuxfun, linuxmint, lovelinux, LPI, LPIC, management, nerd, opensource, php, prova, shell, software, softwarelivre, sql, tech, ti, unix

Você também pode gostar

Cryptomator: Um Guia Completo para Proteger Seus Dados na Nuvem

A Importância da Criptografia na Proteção dos Seus Dados: Veracrypt
